Fine-Tuning Llama-3.1-8B for Function Calling using LoRA
Leveraging Unsloth for fine-tuning with Weights & Biases integration for monitoring and vLLM for model serving
Introduction
Fine-tuning large language models (LLMs) has become essential for adapting pre-trained models to specific tasks and domains. While pre-trained models offer impressive general capabilities, fine-tuning allows us to optimize them for specialized use cases like translation or function calling, domain-specific tasks like legal or finance, and custom applications. One of the key challenges in working with LLMs is the computational resource requirement for fine-tuning. Traditional fine-tuning methods require significant GPU memory and computation time. This is where techniques like LoRA (Low-Rank Adaptation) and frameworks like Unsloth come in, making the process more efficient and accessible.
In this comprehensive guide, we’ll explore how to fine-tune the Llama-3.1–8B model for function calling capabilities using Unsloth, a specialized toolkit designed for optimizing and fine-tuning large language models. We’ll leverage LoRA for efficient parameter updates, integrate Weights & Biases (W&B) for experiment tracking, and later use vLLM for high-performance model inference and serving.

Why Function Calling Matters for Language Models
Function calling in language models enables the AI to interact directly with external systems and perform real-world tasks autonomously. By integrating external functions and APIs, developers can build applications that do more than just generate text — they can solve specific problems, retrieve information, and execute actions based on user inputs.
Function calling in smaller language models (SLMs) is particularly valuable because it allows these models to handle function-calling tasks efficiently on more accessible hardware. Here, function calling capabilities enable tasks like:
- Converting natural language into API calls or generating valid database queries.
- Building conversational knowledge retrieval systems that interact with real-time data.
Unlike large models, SLMs can achieve these interactions with fewer resources when fine-tuned appropriately. Techniques like LoRA allows us to add task-specific functionality without requiring extensive memory, making SLMs practical for real-time applications.
Overview of Tools and Techniques
Unsloth
An optimized framework for LLM fine-tuning that offers:
- Up to 30x faster training speeds and 60% reduced memory usage
- Support for multiple hardware setups (NVIDIA, AMD, and Intel GPUs)
- Intelligent weight optimization techniques for memory efficiency
- Integration with popular fine-tuning methods like Flash-Attention 2
- Compatibility with major LLMs (Mistral, Llama, Gemma)
- Efficient operation on local GPUs and Google Colab
LoRA (Low-Rank Adaptation)
A parameter-efficient fine-tuning method that reduces memory requirements by adding small trainable rank decomposition matrices to existing weights, enabling task-specific adaptations without modifying all model parameters.
Weights & Biases (W&B)
A monitoring platform for tracking training metrics, visualizing performance, and managing experiments.
vLLM
An open-source library that introduces innovative techniques such as PagedAttention and continuous batching to optimize memory usage and enhance throughput, enabling efficient LLM serving and inference optimization.
Step-by-Step Guide to Fine-Tuning and Deployment
Setting Up Weights & Biases
To monitor and log the model’s fine-tuning process, we begin by configuring W&B. The below function handles authentication and initializes a new run with specified project and run name.
import os
import wandb
from dotenv import load_dotenv
load_dotenv()
def setup_wandb(project_name: str, run_name: str):
# Set up your API KEY
try:
api_key = os.getenv("WANDB_API_KEY")
wandb.login(key=api_key)
print("Successfully logged into WandB.")
except KeyError:
raise EnvironmentError("WANDB_API_KEY is not set in the environment variables.")
except Exception as e:
print(f"Error logging into WandB: {e}")
# Optional: Log models
os.environ["WANDB_LOG_MODEL"] = "checkpoint"
os.environ["WANDB_WATCH"] = "all"
os.environ["WANDB_SILENT"] = "true"
# Initialize the WandB run
try:
wandb.init(project=project_name, name=run_name)
print(f"WandB run initialized: Project - {project_name}, Run - {run_name}")
except Exception as e:
print(f"Error initializing WandB run: {e}")
setup_wandb(project_name="<project_name>", run_name="<run_name>")HuggingFace Authentication
In order to download the function-calling dataset by Salesforce and later upload the fine-tuned model, we first need to authenticate our access to the Hugging Face Hub by securely loading and verifying the Hugging Face token from environment variables.
from huggingface_hub import login
hf_token = os.getenv("HUGGINGFACE_TOKEN")
if hf_token is None:
raise EnvironmentError("HUGGINGFACE_TOKEN is not set in the environment variables.")
login(hf_token)Loading the Base Model
This setup loads the Llama-3.1–8B-Instruct model and its tokenizer using Unsloth’s FastLanguageModel, with:
- Configurable sequence length (
max_seq_length=2048) specifies the maximum input sequence length the model can process, often referred to as the model’s context length. - Automatic dtype detection (
dtype=None) for flexible optimization. - 4-bit quantization option (
load_in_4bit=False), allowing default precision for higher model fidelity.
import torch
from unsloth import FastLanguageModel
max_seq_length = 2048 # Unsloth auto supports RoPE Scaling internally!
dtype = None # None for auto detection
load_in_4bit = False # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)Configuring LoRA for Efficient Fine-Tuning
This code configures the Llama-3.1 model for Parameter-Efficient Fine-Tuning (PEFT) using LoRA, enabling efficient fine-tuning of select layers while minimizing memory usage and accelerating training by adapting only specific components instead of the entire model. Here’s a breakdown of each key parameter:
r=16: Sets the rank of LoRA matrices, balancing model performance with memory use.target_modules: Identifies layers like"q_proj"and"k_proj"for targeted fine-tuning.lora_alpha=16: Controls the scaling factor to avoid overfitting.lora_dropout=0: Sets dropout to zero for consistent training.use_gradient_checkpointing="unsloth": Minimizes memory usage, especially for long context lengths.bias="none”: Omits the additional bias termsrandom_state=3407: Ensures reproducible training runs.use_rslora=False: Disables rank-sensitive LoRA, optimizing for standard, less complex tasks.loftq_config=None: Disables LoftQ, which would otherwise use advanced initialization to improve accuracy but at the cost of higher memory at the start.
This setup allows for more resource-efficient fine-tuning while maintaining model performance.
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA rank - suggested values: 8, 16, 32, 64, 128
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0, # Supports any, but = 0 is optimized
bias="none", # Supports any, but = "none" is optimized
use_gradient_checkpointing="unsloth", # Ideal for long context tuning
random_state=3407,
use_rslora=False, # Disable rank-sensitive LoRA for simpler tasks
loftq_config=None # No LoftQ, for standard fine-tuning
)Loading and Processing the Dataset
For our training, we will use Salesforce/xlam-function-calling-60k, which has been specifically designed for function-calling tasks.
To begin fine-tuning, we’ll start with a manageable subset of 15K samples from the dataset instead of using the entire dataset. This allows us to assess the model’s performance early on and make adjustments more efficiently. A sample size of 10–20K strikes a good balance: it’s large enough to yield meaningful insights while keeping memory and training time requirements reasonable.
from datasets import load_dataset
# Loading the dataset
dataset = load_dataset("Salesforce/xlam-function-calling-60k", split="train", token=hf_token)
# Selecting a subset of 15K samples for fine-tuning
dataset = dataset.select(range(15000))
print(f"Using a sample size of {len(dataset)} for fine-tuning.")Using Unsloth’s chat templates, we transform raw data into model-compatible tokens. This step standardizes prompts for function calling, enabling the model to understand and predict outputs in a structured way.
from unsloth.chat_templates import get_chat_template
# Initialize the tokenizer with the chat template and mapping
tokenizer = get_chat_template(
tokenizer,
chat_template = "llama-3",
mapping = {"role" : "from", "content" : "value", "user" : "human", "assistant" : "gpt"}, # ShareGPT style
map_eos_token = True, # Maps <|im_end|> to <|eot_id|> instead
)
def formatting_prompts_func(examples):
convos = []
# Iterate through each item in the batch (examples are structured as lists of values)
for query, tools, answers in zip(examples['query'], examples['tools'], examples['answers']):
tool_user = {
"content": f"You are a helpful assistant with access to the following tools or function calls. Your task is to produce a sequence of tools or function calls necessary to generate response to the user utterance. Use the following tools or function calls as required:\n{tools}",
"role": "system"
}
ques_user = {
"content": f"{query}",
"role": "user"
}
assistant = {
"content": f"{answers}",
"role": "assistant"
}
convos.append([tool_user, ques_user, assistant])
texts = [tokenizer.apply_chat_template(convo, tokenize=False, add_generation_prompt=False) for convo in convos]
return {"text": texts}
# Apply the formatting on dataset
dataset = dataset.map(formatting_prompts_func, batched = True,)Defining Training Arguments
The TrainingArguments setup defines hyperparameters and logging configurations for fine-tuning the model, helping maintain efficient training with well-controlled steps. Each parameter plays a role in optimizing model behavior and monitoring progress effectively.
from transformers import TrainingArguments
args = TrainingArguments(
per_device_train_batch_size = 8, # Controls the batch size per device
gradient_accumulation_steps = 2, # Accumulates gradients to simulate a larger batch
warmup_steps = 5,
learning_rate = 2e-4, # Sets the learning rate for optimization
num_train_epochs = 3,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
optim = "adamw_8bit",
weight_decay = 0.01, # Regularization term for preventing overfitting
lr_scheduler_type = "linear", # Chooses a linear learning rate decay
seed = 3407,
output_dir = "outputs",
report_to = "wandb", # Enables Weights & Biases (W&B) logging
logging_steps = 1, # Sets frequency of logging to W&B
logging_strategy = "steps", # Logs metrics at each specified step
save_strategy = "no",
load_best_model_at_end = True, # Loads the best model at the end
save_only_model = False # Saves entire model, not only weights
)Training with SFTTrainer and Unsloth
The SFTTrainer is configured for supervised fine-tuning with custom tokenization, dataset preprocessing, and memory optimization. The combination with unsloth_train will allow for unsloth's optimized gradient checkpointing, crucial for handling long sequences and reducing memory usage.
from trl import SFTTrainer
trainer = SFTTrainer(
model = model,
processing_class = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = args
)This code captures the intial GPU memory stats at the start of training.
# Show current memory stats
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")Now that we’ve finalized the setup, let’s begin the training of our model.
from unsloth import unsloth_train
trainer_stats = unsloth_train(trainer)
print(trainer_stats)wandb.finish()
After the training process, the below code checks and compares final memory usage, capturing the memory used specifically for LoRA training and calculating memory percentages.
# Show final memory and time stats
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")We can visualize the training metrics and system metrics, such as memory usage, training duration, training loss, and accuracy on Weights & Biases to gain better insights into our model’s performance over time.
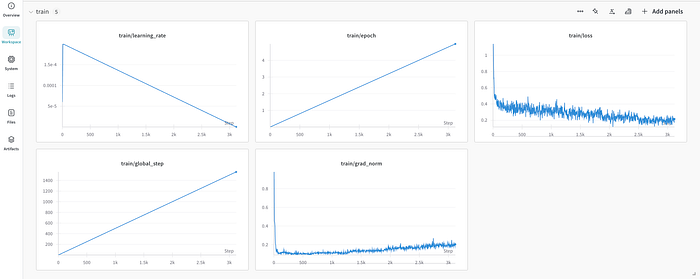
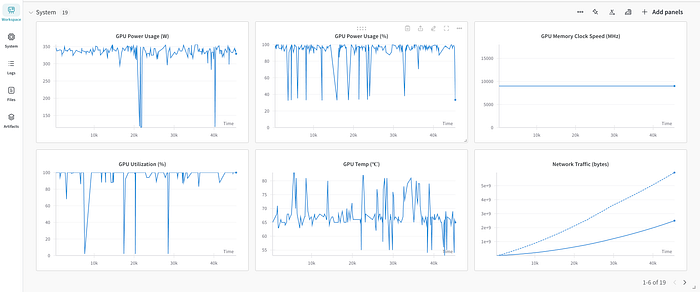
Saving and Deploying the Model
After training, the fine-tuned model is saved locally and pushed to Hugging Face’s hub for further access and deployment. However, this only saves the LoRA adapters.
# Local saving
model.save_pretrained("<lora_model_name>")
tokenizer.save_pretrained("<lora_model_name>")
# Online saving
model.push_to_hub("<hf_username/lora_model_name>", token = hf_token)
tokenizer.push_to_hub("<hf_username/lora_model_name>", token = hf_token) For merging the LoRA adapters with the base model and save the model to 16-bit precision for optimized performance with vLLM, use:
# Merge to 16bit
model.save_pretrained_merged("<model_name>", tokenizer, save_method = "merged_16bit",)
model.push_to_hub_merged("<hf_username/model_name>", tokenizer, save_method = "merged_16bit", token = hf_token)Fine-Tuned Model Evaluation
We’ll begin by loading our fine-tuned model, which can be either saved locally on disk or retrieved from Hugging Face, along with the tokenizer.
from unsloth import FastLanguageModel
from transformers import TextStreamer
max_seq_length = 2048
dtype = None
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "<model_name>", # Trained model either locally or from huggingface
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inferenceWe can now define our utility functions designed for data retrieval to enhance user experience. In this tutorial, we will make use of the following functions for demonstration purposes:
get_current_date: Returns the current date formatted as 'YYYY-MM-DD'.get_current_weather: Retrieves weather data for a specified location using the OpenWeatherMap API.celsius_to_fahrenheit: Converts temperature from Celsius to Fahrenheit.get_nasa_picture_of_the_day: Fetches details about NASA's daily image.get_stock_price: Provides stock prices for a specified ticker symbol and date using data from Alpha Vantage.
import re
import json
import requests
from datetime import datetime
import nasapy
WEATHER_API_KEY = os.getenv("WEATHER_API_KEY")
NASA_API_KEY = os.getenv("NASA_API_KEY")
STOCK_API_KEY = os.getenv("STOCK_API_KEY")
def get_current_date() -> str:
"""
Fetches the current date in the format YYYY-MM-DD.
Returns:
str: A string representing the current date.
"""
print("Getting the current date")
try:
current_date = datetime.now().strftime("%Y-%m-%d")
return current_date
except Exception as e:
print(f"Error fetching current date: {e}")
return "NA"
def get_current_weather(location: str) -> dict:
"""
Fetches the current weather for a given location (default: San Francisco).
Args:
location (str): The name of the city for which to retrieve the weather information.
Returns:
dict: A dictionary containing weather information such as temperature, weather description, and humidity.
"""
print(f"Getting current weather for {location}")
try:
weather_url = f"http://api.openweathermap.org/data/2.5/weather?q={location}&appid={WEATHER_API_KEY}&units=metric"
weather_data = requests.get(weather_url)
data = weather_data.json()
weather_description = data["weather"][0]["description"]
temperature = data["main"]["temp"]
humidity = data["main"]["humidity"]
return {
"description": weather_description,
"temperature": temperature,
"humidity": humidity
}
except Exception as e:
print(f"Error fetching weather data: {e}")
return {"weather": "NA"}
def celsius_to_fahrenheit(celsius: float) -> float:
"""
Converts a temperature from Celsius to Fahrenheit.
Args:
celsius (float): Temperature in degrees Celsius.
Returns:
float: Temperature in degrees Fahrenheit.
"""
print(f"Converting {celsius}°C to Fahrenheit")
try:
fahrenheit = (celsius * 9/5) + 32
return fahrenheit
except Exception as e:
print(f"Error converting temperature: {e}")
return None
def get_nasa_picture_of_the_day(date: str) -> dict:
"""
Fetches NASA's Picture of the Day information for a given date.
Args:
date (str): The date for which to retrieve the picture in 'YYYY-MM-DD' format.
Returns:
dict: A dictionary containing the title, explanation, and URL of the image or video.
"""
print(f"Getting NASA's Picture of the Day for {date}")
try:
nasa = nasapy.Nasa(key = NASA_API_KEY)
apod = nasa.picture_of_the_day(date = date, hd=True)
title = apod.get("title", "No Title")
explanation = apod.get("explanation", "No Explanation")
url = apod.get("url", "No URL")
return {
"title": title,
"explanation": explanation,
"url": url
}
except Exception as e:
print(f"Error fetching NASA's Picture of the Day: {e}")
return {"error": "Unable to fetch NASA Picture of the Day"}
def get_stock_price(ticker: str, date: str) -> tuple[str, str]:
"""
Retrieves the lowest and highest stock prices for a given ticker and date.
Args:
ticker (str): The stock ticker symbol, e.g., "IBM".
date (str): The date in "YYYY-MM-DD" format for which you want to get stock prices.
Returns:
tuple: A tuple containing the low and high stock prices on the given date, or ("none", "none") if not found.
"""
print(f"Getting stock price for {ticker} on {date}")
try:
stock_url = f"https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol={ticker}&apikey={STOCK_API_KEY}"
stock_data = requests.get(stock_url)
stock_low = stock_data.json()["Time Series (Daily)"][date]["3. low"]
stock_high = stock_data.json()["Time Series (Daily)"][date]["2. high"]
return stock_low, stock_high
except Exception as e:
print(f"Error fetching stock data: {e}")
return "none", "none"
available_function_calls = {"get_current_date": get_current_date, "get_current_weather": get_current_weather, "celsius_to_fahrenheit": celsius_to_fahrenheit,
"get_nasa_picture_of_the_day": get_nasa_picture_of_the_day, "get_stock_price": get_stock_price}Next, we’ll create a list of available functions along with their function definitions. The below code defines the metadata for the available functions, including their names, descriptions, and required parameters. This is essential for integrating the functions into a chat-like interface where the model can understand which functions to call based on user queries.
functions = [
{
"name": "get_current_date",
"description": "Fetches the current date in the format YYYY-MM-DD.",
"parameters": {
"type": "object",
"properties": {},
"required": [],
},
},
{
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and country code, e.g. San Francisco, US",
}
},
"required": ["location"],
},
},
{
"name": "celsius_to_fahrenheit",
"description": "Converts a temperature from Celsius to Fahrenheit.",
"parameters": {
"type": "object",
"properties": {
"celsius": {
"type": "number",
"description": "Temperature in degrees Celsius.",
}
},
"required": ["celsius"],
}
},
{
"name": "get_nasa_picture_of_the_day",
"description": "Fetches NASA's Picture of the Day information for a given date.",
"parameters": {
"type": "object",
"properties": {
"date": {
"type": "string",
"description": "Date in YYYY-MM-DD format for which to retrieve the picture.",
}
},
"required": ["date"],
},
},
{
"name": "get_stock_price",
"description": "Retrieves the lowest and highest stock price for a given ticker symbol and date. The ticker symbol must be a valid symbol for a publicly traded company on a major US stock exchange like NYSE or NASDAQ. The tool will return the latest trade price in USD.",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "The stock ticker symbol, e.g. AAPL for Apple Inc.",
},
"date": {
"type": "string",
"description": "Date in YYYY-MM-DD format",
}
},
"required": ["ticker", "date"],
},
}
]
available_tools_list = {
"functions_str": [json.dumps(x) for x in functions],
}In this code segment, we specify the user question and define a structured set of chat messages, along with a JSON list of the available functions, to be used in the tokenizer chat template for the model to process.
query = "What is the current weather at the headquarters of IBM? Also, can you provide the stock prices for the company on October 29, 2024?"
chat = [
{"role":"system","content": f"You are a helpful assistant with access to the following function calls. Your task is to produce a sequence of function calls necessary to generate response to the user utterance. Use the following function calls as required.\n{available_tools_list}"},
{"role": "user", "content": query }
]The model then determines the appropriate function call based on the intent of the user query, as indicated by the function call name in the generated response.
inputs = tokenizer.apply_chat_template(
chat,
tokenize = True,
add_generation_prompt = True, # Must add for generation
return_tensors = "pt",
).to("cuda")
outputs = model.generate(input_ids = inputs, max_new_tokens = 1024, use_cache = True)
response = tokenizer.batch_decode(outputs)[0]
print(response)We can also utilize the TextStreamer class to stream the generated text output, enabling real-time response streaming.
text_streamer = TextStreamer(tokenizer, skip_prompt = True)
_ = model.generate(input_ids = inputs, streamer = text_streamer, max_new_tokens = 512, use_cache = True, pad_token_id = tokenizer.eos_token_id)
Now that our model has told us what function(s) to call and with what parameters, we can execute them and pass their output back to the LLM so that it can generate the final answer back to the user.
To execute this function effectively, we will extract the relevant arguments from the model’s output, ensuring we have all the necessary details for a seamless execution. This approach allows us to dynamically utilize the selected functions based on user input, enhancing the overall interaction experience.
def extract_content(text):
# Define the regex pattern to extract the content
pattern = r"<\|start_header_id\|>assistant<\|end_header_id\|>(.*?)<\|eot_id\|>"
match = re.search(pattern, text, re.DOTALL)
if match:
return match.group(1).strip()
return None
parsed_response = json.loads(extract_content(response))
print(parsed_response)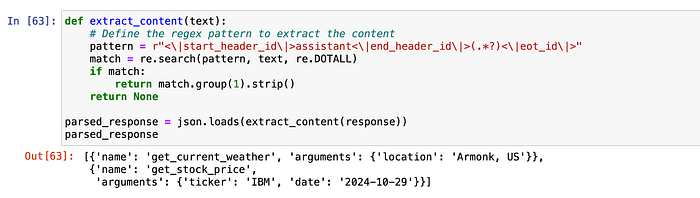
The below code processes the parsed response by executing the necessary function calls to gather information based on the user query. Each function call’s result is appended to the chat history, and the system message is updated to reflect its current state. The model is then prompted again to generate a final response based on the information collected from function calling.
if parsed_response:
new_system_content = "You are a helpful assistant. Answer the user query based on the response of the specific function call or tool provided to you as context. Generate a precise answer for given user query, synthesizing the provided information."
for res in parsed_response:
obtained_function = res.get("name")
arguments = res.get("arguments")
function_description = next(item['description'] for item in functions if item['name'] == obtained_function)
function_to_call = available_function_calls[obtained_function]
response = function_to_call(**arguments)
print(response)
chat.append({
"role": "tool",
"content": f"The tool - '{obtained_function}' with the function definition - '{function_description}' and function arguments -'{arguments}' yielded the following response: {response}\n."
})
for message in chat:
if message['role'] == 'system':
message['content'] = new_system_content
inputs = tokenizer.apply_chat_template(
chat,
tokenize = True,
add_generation_prompt = True,
return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt = True)
_ = model.generate(input_ids = inputs, streamer = text_streamer, max_new_tokens = 512, use_cache = True, pad_token_id = tokenizer.eos_token_id)
else:
print("No function call found in the response")
Setting Up vLLM for Fast Inference
This code configures the vLLM framework for high-throughput and memory-efficient inference by loading our saved model and initializing it with specified parameters.
from vllm import LLM
from vllm.sampling_params import SamplingParams
model_name = "<hf_username/model_name>"
sampling_params = SamplingParams(max_tokens=768)
llm = LLM(
model=model_name,
max_model_len=2048,
tokenizer_mode="auto",
tensor_parallel_size=1,
enforce_eager=True,
gpu_memory_utilization=0.95
)
llm_prompt = """
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant with access to the following function calls. Your task is to produce a sequence of function calls necessary to generate response to the user utterance. Use the following function calls as required.
{available_tools_list}<|eot_id|><|start_header_id|>user<|end_header_id|>
{query}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
input_prompt = llm_prompt.format(available_tools_list=available_tools_list, query=query)
output = llm.generate([input_prompt], sampling_params)
generated_text = output[0].outputs[0].text
print(f"Generated text: {generated_text!r}")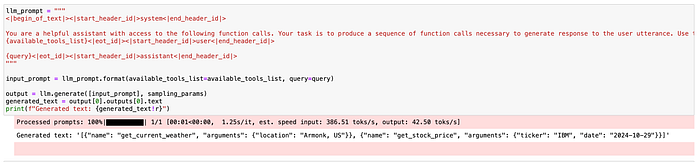
Conclusion:
Fine-tuning the Llama-3.1–8B model using Unsloth and LoRA allows for effective adaptation to custom domains and specific tasks while optimizing resource usage. The use of techniques like LoRA not only enhances fine-tuning efficiency but also reduces memory consumption, making it a practical choice for a variety of applications.
Additionally, by incorporating Weights & Biases (WandB) for experiment tracking, you can streamline your workflow and gain valuable insights into your fine-tuning process. Leveraging vLLM ensures high throughput and memory-efficient model serving, enabling robust performance in real-world scenarios.
By following the strategies outlined in this guide, you can successfully fine-tune your models to meet your unique needs, ultimately achieving high-quality results with minimal resources.