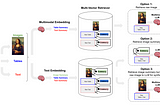
Gautam ChutaniMulti-Modal RAG: A Practical GuideUsing vLLM to serve models for Multimodal Text Summarization, Table Processing, and Answer Synthesis2d ago2d ago
Gautam ChutanivLLM: Efficient Serving with Scalable PerformanceA guide to serving multimodal models like LLaVA on a CPU with vLLM4d ago4d ago
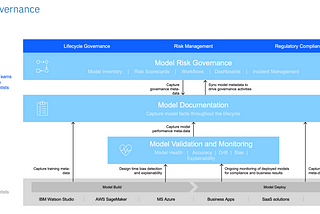
Gautam ChutaniPredictive Model Monitoring with IBM watsonx.governanceCo-Author: Nishant Kumar and VarshaSep 1Sep 1
Gautam ChutaniDeploy Seamlessly with Red Hat OpenShift Local for MacIn today’s fast-paced development environment, having a streamlined local setup for deploying and testing backend applications is…Jul 28Jul 28
Gautam ChutaniRevolutionizing Prompt Engineering with DSPyDeclarative Self-Improving Language Programs for Enhanced LM ReliabilityJun 27Jun 27
Gautam ChutaniUnderstanding Source Attribution in RAGLeveraging ProtoDash for Context AttributionJun 25Jun 25
Gautam ChutaniRHEL AI vs OpenShift AI vs IBM watsonx: Navigating the AI EcosystemIntegrating AI into Enterprise Workflows made SimplerJun 20Jun 20
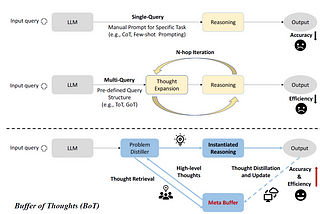
Gautam ChutaniEnhancing LLMs with Buffer of Thoughts (BoT): A New Frontier in AI ReasoningCo-Author: Jayesh RanjanJun 15Jun 15
Gautam ChutaniFrom API to UI: LLM Response Streaming with IBM watsonx.aiCo-Author: Himanshu BohraJun 151Jun 151